采集數據處理:HTML標簽過濾
HTML標簽具有其語義和默認樣式,例如a標簽代表超鏈接(可點擊跳轉設置的url),p標簽代表文本段落(默認換行顯示)等,所以HTML標簽在頁面顯示的效果就各有不同,有些會影響排版布局(分行,表格等),有些是媒體展示(圖片,視頻等)。
簡數采集器的 “HTML標簽過濾” 功能可指定只保留哪些HTML標簽,根據HTML標簽類型會出現兩種情況:
1. 標簽中有文本的默認會保留,把標簽和排版格式去除,例如p標簽,a標簽等;
2. 標簽是資源標簽,即類似img標簽,video標簽等,會把這些媒體資源內容刪除;
操作方法
1. 查看HTML標簽過濾功能
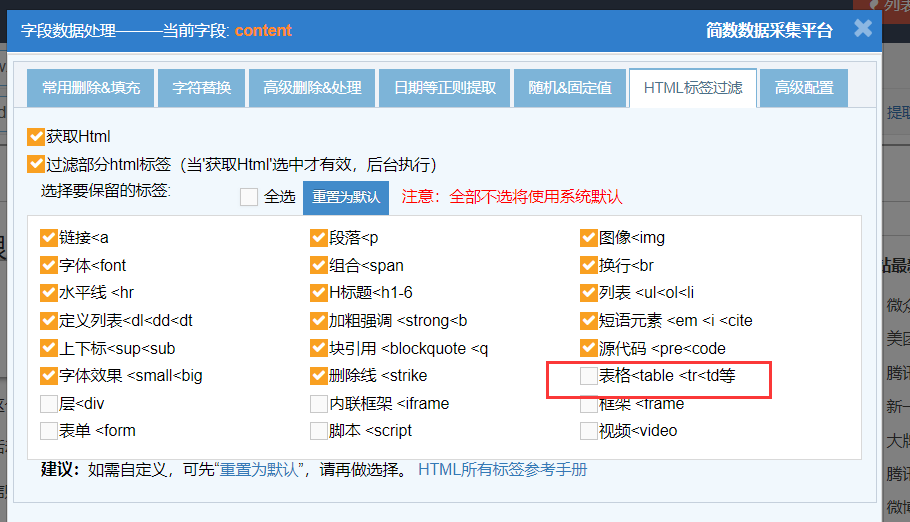
在簡數采集器某個任務的詳情提取器里,點擊進入content字段的字段數據處理頁面 --》點擊切換到 “HTML標簽過濾” 設置,勾上的是保留的標簽。
簡數采集器已默認過濾不需要不常用的標簽,只保留常用的html標簽,若無特殊需求用戶一般不需要修改了。

2. 指定HTML標簽保留或過濾
“HTML標簽過濾” 功能生效的前提是,“獲取Html” 和 “過濾部分html標簽” 選項都勾上,然后下方的標簽配置區域:勾選上的是保留,沒勾選的是要過濾不保留。
2-1)例如采集的文章沒排版時,可以嘗試保留div標簽解決。

2-2)例如不需要表格形式的顯示,只需要其文本內容,請把table系列標簽勾選掉后保存;